Why and How GraphQL Is The Best Tool For Efficient Data Fetching- GO Tech Blog

Just recently our GO Dev team embarked on a project to integrate Monday.com cloud service to one of our internal components. Their API was GraphQL and that's why we came to work with this technology.
GraphQL is an API standard that provides a more efficient, powerful and flexible alternative to REST. It was developed and open-sourced by Facebook. At its core, GraphQL enables declarative data fetching where a client can specify exactly what data he needs from an API. Instead of multiple endpoints that return fixed data structures, a GraphQL server exposes only a single endpoint and responds precisely with the data the client asked for.
In this technical article we will explain the what, why, and how you can use GraphQL based on our recent experience.
GraphQL vs REST
GraphQL was developed to cope with the need of more flexibility and efficiency. It solves many of the shortcomings and inefficiencies that developers experience when interacting with REST APIs.
Data Fetching
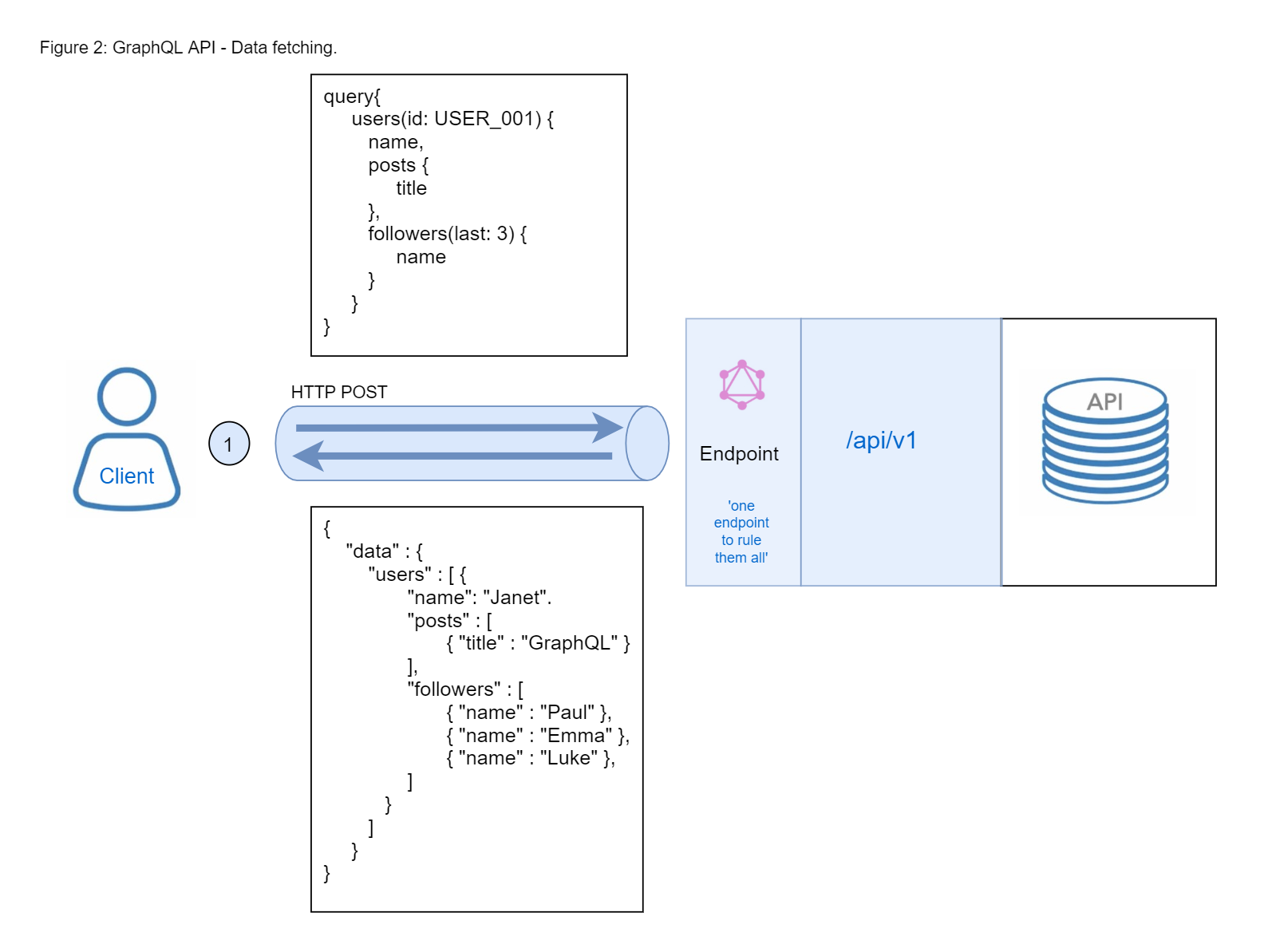
Let us assume a scenario where an application needs to access information on a user, his posts and his followers in a blogging database. To be more specific, the client wants to get a particular user name, all the titles of his posts, and the name of his followers, possibly limiting the amount returned.
With a typical REST API, you would gather the data by accessing multiple endpoints. Here the client first called the "users" endpoint to get the name of user "USER_001". The second call was to the "posts" endpoint to get the titles of all posts posted by "USER_001’', and finally a last call to the "followers" endpoint return the followers of the user (see Figure 1).
 |
| Figure 1 |
- Accessing multiple endpoints to gather the desired data. Three requests were made to fetch the data. Each request added to the network traffic and overhead, and thus increasing the possibility of network latency.
- Over-fetching or under-fetching. Over-fetching happens because the only way for a client to download data is by hitting endpoints that return fixed data structures. Under-fetching is when a specific endpoint doesn’t provide enough of the required information.
All the three requests returned data that was not needed by the client. The user id and address, the posts content, and the followers’ id and address were returned in the rigid response, and discarded by the client. Nevertheless this was data that was transferred over the network.
The above problems raise from the inflexible nature of the typical REST API.
 |
| Figure 2 |
- Accessing a single endpoint to gather the desired data. One request was made to fetch the data. No extra network traffic and overhead.
- No over-fetching or under-fetching. The client specified exactly the data that was needed. In this example, only the name of a specific user was returned, along with the title of his posts and the names of his last 3 followers, as requested by the client. No extra data was transferred over the network.
- Insightful analytics on the server. As the client specifies exactly what information it needs, it is possible to gain a deep understanding of how the available data is being used. This can, for example, help in evolving an API and remove certain functionality that is no longer needed.


The GraphQL Schema - a closer look


- Objects are made up of primitive and/or other objects.
- Access to the API is ONLY through the root types, which define the operations of the API.
- The root types are objects themselves.
- Following from 3, a request to the server reduce itself to just defining the fields of an object that are required.
- Objects are linked together through their relation. Thus a single query request can fetch any data from the schema. For example, starting from the "query" object, you can also access the users, and since the "user" has a relationship or is related to both "post" and "follower" you can also fetch these.
- The object can accept arguments in GraphQL. Arguments serve the same purpose as your traditional query parameters or URL segments in a REST API. You can pass them into the query fields of an object to specify how the server should respond to a request. Arguments can be mandatory or optional.


Client Query examples using the schema




The GraphQL Schema - a server perspective
 |
| Figure 4 |
The GraphQL server has 3 major components (see figure 4): The Schema, The Parser and The Resolver.
- Query Validation. Once a query is received from the client, the parser will match the object in the query with the schema. If the object type and the types of its fields do not match with the schema, then this will result in an error response. If the validation is successful, it goes to step 2.
- Query parsing and response building. Here the parser will iterate on each object and field type inside the query and for each type it will call a "resolver function" to get the data for that type. The "resolver function" is part of the resolver component. Note that the parser has no knowledge how to fetch the data, it just maps each "type" to a "resolver function". It is the "resolver function" which is responsible to fetch the data and pass it back to the parser.

GraphQL over HTTP
 |
| Figure 5 |

GraphQL @ GO



About the Author and the Team

.png)


Comments
Post a Comment